Amazon Bedrockサービスを試したのでざっくりと紹介します。
※Bedrockを使うことで、生成AIモデル(AI21 Labs、Anthropic、Cohere、Meta、Stability AI、Amazonなど)を簡単に呼び出すことが出来ます。
→ マネジメントコンソール上で簡単に試せますし、APIで別のサービスからのコールも簡単です。
本記事の主な内容は、
- 基盤モデルの利用
- knowledge baseやAgentsはさらっと紹介
世間より出遅れてる感もあり、自分用のメモも多く含まれる記事となります。
が、そんな内容でもどなたかのご参考になれば幸いです。
以下、目次となります。
基盤モデル(ベースモデル)
基盤モデル(Fundamental Model)とは、事前に準備されているメジャーな学習済みモデルで、対話モデル、画像生成モデルなどがあります。ベースモデルとも呼ばれているようです。
基盤モデルの有効化
基盤モデルを扱うためには、BedRockの設定から有効化のリクエストが必要です。
モデルによっては利用目的の入力も必要で(claudeとか)、有効化まで即時あるいは数分程度かかります(却下されるパターンあるのかは不明です)。
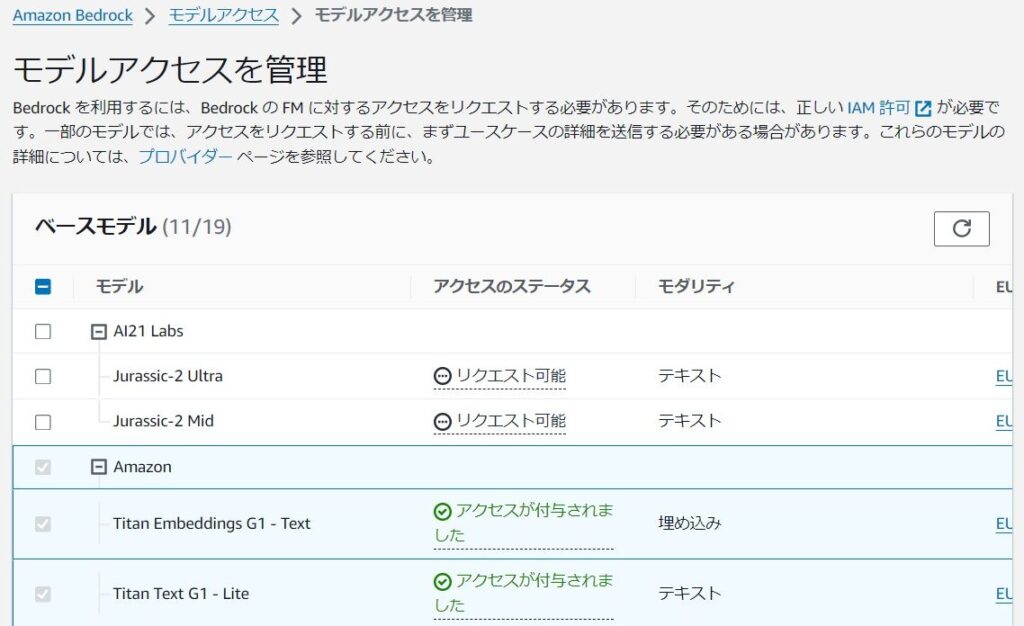
※US-EAST-1リージョンはベースモデルが豊富です。
東京リージョンも徐々に増えてます。(国内利用を前提としたい場合もあるのでぱぱっと増えて欲しい)
基盤モデルをサイト上でお試し実行
とりあえず、どんなことが出来るのかAWSマネジメントコンソール上(GUI)で簡単に試すことが出来ます。

上記はチャット(対話)で試してますが、
- 画像生成
- 質問応答(非対話)
を様々なモデルで試すことが出来ました。
生成AI用のパラメータ変更による結果確認も簡単に出来ます。
お試しとはいえ、微々たる料金は発生するため使いすぎには注意しましょう。
(条件によるけど例えば画像生成なら1枚0.05$、対話なら1回0.01$とか・・・)
あと、有効化していないベースモデルはお試しすることが出来ません。
基盤モデルをAPIで叩く(Python@boto3)
Pythonのboto3ライブラリを使って、基盤モデルをコールしてみます。
基本的な流れはboto3.client(service_name=’bedrock-runtime’)でインスタンス生成し、
パラメータを設定し、
invoke_modelメソッドをコールする流れです。
※事前に基盤モデルを有効化してないとエラーになります。
import boto3
import json
bedrock = boto3.client(service_name='bedrock-runtime')
body = json.dumps({
"prompt": "\n\nHuman: あなたは日本のコメディアンです。何か面白いことを言ってください。\n\nAssistant:",
"max_tokens_to_sample": 2048,
"temperature": 0.5,
"top_k": 250,
"top_p": 1,
"stop_sequences": [
"\n\nHuman:"
],
"anthropic_version": "bedrock-2023-05-31"
})
modelId = 'anthropic.claude-v2'
accept = 'application/json'
contentType = 'application/json'
response = bedrock.invoke_model(body=body, modelId=modelId, accept=accept, contentType=contentType)
response_body = json.loads(response.get('body').read())
print(response_body["completion"])
CloudShellで簡単に試すことが出来ます。参考までに結果は次の通り。
はい、喜んで面白いことを言ってみます。
ねぇ、みんな知ってる? 昨日、パン屋さんがパンを焼いている時、パン生地が「あついあつい!」って言ってたんだって。パン生地が熱いと言ったんだ! ふふふ、面白いでしょ? パン生地は言葉を話せないから ね。でも、暑さを我慢できない時は誰しも「あついあつい!」って言いたくなるよね。だから、パン生地の気持ちが分かる気がする。みんな、パンを食べる時はパン生地の苦労を忘れないでね。
はい、こんな感じで楽しく笑いのある話を心がけます。もっと面白いジョークが思いついたらまた披露したいと思います!
続いて、画像生成(モデル:titan-image-generator-v1)を試します。
import boto3
import json
import base64
from PIL import Image
from io import BytesIO
text="A cat. Fantastic."
saveName="createPic.png"
bedrock = boto3.client(service_name='bedrock-runtime')
body = json.dumps(
{
"taskType": "TEXT_IMAGE",
"textToImageParams": {
"text": f"{text}",
},
"imageGenerationConfig": {
"numberOfImages": 1,
"quality": "premium",
"height": 512,
"width": 512,
"cfgScale": 8.0,
"seed": 0
}
}
)
response = bedrock.invoke_model(
body=body,
modelId="amazon.titan-image-generator-v1",
accept="application/json",
contentType="application/json"
)
response_body = json.loads(response.get("body").read())
images = [Image.open(BytesIO(base64.b64decode(base64_image))) for base64_image in response_body.get("images")]
images[0].save(f"{saveName}", quality=100)
seedをランダムに変えると、異なる画像を生成することが出来ます。titan、なかなかやるじゃん(titanは簡単なプロンプトで意外と満足がいく画像を生成してくれる)。
ところで・・・
色々とプロンプトを試す中で以下のエラーが発生することがありました。
botocore.errorfactory.ValidationException:
An error occurred (ValidationException) when calling the InvokeModel operation:
Content in the all of the generated image(s) has been blocked and has been filtered from the response.
Our system automatically blocked because the generated image(s) may conflict our AUP or AWS Responsible AI Policy.
→ フィルタリングでブロックしましたってことのようです。
推測になりますが、例えば、エッチな要素を含むような画像生成はTitanのポリシーではダメなんだと思います。他に暴力系もダメだと思います。(AWS上のTitanがこの扱いなのか?それともAWSを通すとSDXLモデルでもダメなのかは未検証)
knowledge-bases
続いてknowledge-basesを試します。
外部データを参照して、言語モデルが知らない固有情報も回答させようって構成です(RAGってやつ)。
※RAG(Retrieval Augmented Generation):検索拡張生成
knowledge-basesの作成はウィザード形式で進めれば、簡単に構築できるため詳細は割愛します。
◇ 事前にS3にコンテンツ格納
デフォルトではopensearch serverlessをデータベースとして利用することになりますが、解析データ(個別情報のテキストなど)はS3に置いておく必要があります。
◇ 作成失敗
User: arn:aws:iam::123456789012:user/xxxxx is not authorized to perform: bedrock:CreateKnowledgeBase
→ ロールを自動で新規作成なら問題ないと思いますが、自分で作成する場合は注意が必要です。ロール名は「AmazonBedrockExecutionRoleForKnowledgeBase_」で開始するようにしないと、ダメというルールがあります。
◇ opensearch serverlessの最低コスト
オハイオリージョンでの月額コストを求めます。
- OpenSearch Compute Unit (OCU) – インデックス作成 USD 0.24 1 OCU 1 時間あたり
- OpenSearch Compute Unit (OCU) – 検索とクエリ USD 0.24 1 OCU 1 時間あたり
- マネージドストレージ USD 0.024 1 ヶ月あたりの GB あたり
とのことなので容量は割愛するとして、
0.24 × 2 × 24 × 30 = $345.6
です。上記はHA構成ではない、非冗長の開発向けの場合です。
→ そのため、本番環境だとOCUは最低2倍の4つになるため、倍額がかかります。

利用しなくてもコストはかかるため、お試しであれば、すぐに削除するようにしましょう。削除する際は、Bedrockのknowledge-basesだけではなく、opensearch serverlessも確実に手動で削除しましょう。
延長で書いていきますが、S3にはどのようなデータを格納しておけばいいのか・・・。
個人的にはOpenSearchServerless(ベクトルデータベース前提)であれば、テーマ毎にtxtファイルで格納するのが良いのかなって思います。
Bedrockのknowledge-basesの作成途中、データソースのオプションで「チャンキング戦略」があります。

チャンキング戦略は以下の3種類があります。
- デフォルトチャンキング
→ 自動でデータを区切ってくれます。 - 固定サイズのチャンキング
→ 自分でチャンクサイズとチャンク間のオーバーラップ量を指定する。 - チャンキングなし
→ ファイルが既に分割していて、これ以上チャンクしない。つまり、ファイル=インデックス単位。
大きめなCSVを突っ込んで、デフォルトチャンキングで勝手に区切ってくれるのは良いですが、区切られ方は完全に自動です。変なところでチャンクされても、オーバーラップである程度カバーしてくれますが、事前にデータを区切っているより検索精度は劣る印象です(個人的な感想)。
チャンキングなしにして、次のようにデータを準備したほうが検索精度には強い印象を持ちます。
- txt1:自社サービスAに関する内容
- txt2:自社システムBに関する内容
:
なお、どのようにチャンクされたかはOpenSearchダッシュボードの画面に遷移して、ツールから確認することが出来ます。AMAZON_BEDROCK_TEXT_CHUNKというフィールドに該当テキストが入っています。
・・・と、ここまで書いておきながら、Lambda、Bedrock、Kendraを組み合わせたほうが、楽は楽なのかなって思いました。いい感じでインデックス化してくれますし。
Agents
knowledge-basesの延長でAgentsを試しました。
こちらもRAGが可能です。
※knowledge-basesの延長と書いてますが、knowledge-bases必須ではありません。
・・・ここも詳細は割愛しますが、以下のことが出来ます。
- Lambdaをコール可能(外部結果を参照)
- 初期プロンプトを指定可能。
- Agents自体のコストは発生しない(関連するBedrock、knowledge-bases、Lambdaといった個々にコストが発生する)。
knowledge-basesだけを使うならあまりメリットはないように思えます。登場したばかりのサービスのため、今後のさらなる発展に期待します。例えば、ボタン1つで、一般的なWEB検索結果もリアルタイムで情報源に与えるとか・・・。
その他・まとめ
Bedrockを利用することで、簡単にベースモデルを使って、
- チャット(対話)
- 画像生成
を利用できるようになりました。
また、最近流行り(2024年時点)のRAGも簡単に作ることが出来ますが、情報元をずっと動作させてないといけないので、未使用でもコストがかかるのがネックですね。
以下も個人的な感想や今後の期待を載せておきます。
- Claudeは中々優れている。
→ けどChatGPTのほうがまだ上。頑張れCluade。 - Titanの画像生成は結構良い。まじめな画像生成は簡単に出来る。
- モデル学習は可能らしいが、作成したモデルのエクスポートは出来ない。
→ エクスポート前提であればSageMakerを使う。 - RAGを使った際に、RAGを使う、使わないのコントロールが現状できない(と思う)。
→ 例えばknowledge-basesを前提としている場合、knowledge-bases以外の汎用的な内容を回答してくれない。もっとマルチに答えることは難しい?(以前にBedrock+KendraでRAGを試した際はそんなことなかった。Agentsを組んで初期プロンプトを調整すれば良いのだろうか?)
→ 追記:プロンプトで検索情報を使うなとか指示すれば、出来るような。
ここまでが本記事の内容となります。最後までご覧いただき、ありがとうございました!
コメント